 To backup or not to backup.
To backup or not to backup.
As a saying goes, “There are two groups of people the ones who do backups and the ones who will be doing them”. As the first group has little to worry about this article is focused on those who are about to find their perfect backup solution. Some Linux knowledge is required, though. A pefect reader is someone who owns no more than a handful of systems and praises security above all.
3-2-1 backup strategy that is recognized as a best practise tells you to keep 3 copies of data on 2 different media types with 1 off-site backup. Different media types will give you security not only against things like moisture or strong electomagnetic radiation but also different media types tend to age at different rates.
Backups fall into one of the three categories: Full, Differential and Incremental. A full backup is no less than a copy of your data. For practical reasons this is not something you would do on a daily basis. For a 100GB worth of data you will get 1TB after only 10 snapshots. And the more snapshots you keep the better. If you keep only a single version and you destroy your data you have only a day or so to figure it out. Otherwise your change will propagate to this only copy and destroy it altogether. Differential backups can mitigate this problem by storing only changes from the last full backup. And to restore your backup you need to get to the last full backup and apply the differential one.
Can we do better? Of course we can. We can keep differences from differential backups the same way we do for the full ones. And this is exactly the third category we were to discuss. Incremental backups are the most space efficient of the three. This, however comes at the price of comlpexity and durability. If you do a full backup on Jauary the first and incremental ones throughout the year you will need to apply 364 deltas if thing go awry on December 30th. If the risk of data corruption of one chunk is P then what you aim for is 364*P.
There are a variety of media one can use for backup. They differ in size, durability, cost and ease of use. Here are some examples:
| Medium type | Capacity in GB | Life span in years | Price per TB |
|---|---|---|---|
| CD | 0.7 | 5-10 | $270 |
| DVD | 4.7 | 5-10 | $48 |
| M-Disc | 4.7 | 1000 | $750 |
| M-Disc BD-R | 25-100 | ? | $184 |
| BD-R LTH | 25-100 | 5-10 | $22 |
| BD-R HTL | 25-100 | 50-300 | $36 |
| Memory cards | 0-1000 | ~5 | $270 |
| SSD | 0-8000 | 5-10 | $136 |
| HDD | 0-12000 | ~5 | $30 |
| LTO | 2500-12000 | 30 | $11 |
The question is: what does it mean for M-Discs to have a life-span of a thousand years? Does it always fail the year after? Do all the disks live that long? The short answer is no. 1000 years is the mean life span so you may expect half the disks to fail before with some even way before. Milleniata, the company behind the brand also claims that 95% of disks will make it to around 500 years which gives more insight.
By the looks of it there are four items worth attention here: LTO, M-Disc BD-R and BD-R HTL and of course good old HDD. LTO is not something you would use at home unless you have a tape library down in your basement. M-Disc BD-R and a normal BD-R are more common than not. They share the form factor and storage size of 25GB (BD-XL 100GB). M-Discs can even be read in normal BD players but it takes an M-Disc certified device to burn one. What’s really different between the two is the price and the longevity claims. One can find some studies suggesting that both M-Disks and high quality BD-R are more or less the same in terms of longevity.
Now, once we have chosen the medium type for our backup (my choice is HDD because of the ease of use for automated backups plus most important thigs to me also go on BD-R HTL) we have to find out where to store our off-site copy. There are a lot of options here as well. But the choice is somewhat simpler. We will consider only cloud storage and providers supported by the tool we will use.
Our requirements for a perfect backup solution:
- full automation
- runs periodically
- encrypts our data
- splits data into volumes of a given size
- supports incremental backups
- free of charge
- runs on Linux (ARM distros included)
Duplicity is a tool that meets all of these points. It’s a really simple tool that backs up one folder to another. You can run it as simply as:
$ duplicity one_directory file:///home/user/another_directory
Local and Remote metadata are synchronized, no sync needed.
Last full backup date: none
No signatures found, switching to full backup.
--------------[ Backup Statistics ]--------------
StartTime 1607801729.48 (Sat Dec 12 20:35:29 2020)
EndTime 1607801732.47 (Sat Dec 12 20:35:32 2020)
ElapsedTime 2.99 (2.99 seconds)
SourceFiles 2
SourceFileSize 100004096 (95.4 MB)
NewFiles 2
NewFileSize 100004096 (95.4 MB)
DeletedFiles 0
ChangedFiles 0
ChangedFileSize 0 (0 bytes)
ChangedDeltaSize 0 (0 bytes)
DeltaEntries 2
RawDeltaSize 100000000 (95.4 MB)
TotalDestinationSizeChange 100256475 (95.6 MB)
Errors 0
-------------------------------------------------
This will create at least 3 files with similar names to the ones below:
-rw------- 1 w w 599 gru 9 duplicity-full.20201212T175748Z.manifest
-rw------- 1 w w 96M gru 9 duplicity-full.20201212T175748Z.vol1.difftar.gz
-rw------- 1 w w 574K gru 9 duplicity-full-signatures.20201212T175748Z.sigtar.gz
- manifest - contains information of the files (or part of the files) included in the backup volumes along with hashes of the volumes
- difftar - actual data split into volumes of a specified size (current default: 200MB, previously: 25MB)
- signature - hashes of data in the backup, this can be used to find out what has changed since the last backup and to generate delta
If we rerun this commandt will find out first that there is a full backup and send only changes.
Local and Remote metadata are synchronized, no sync needed.
Last full backup date: Sat Dec 12 20:35:29 2020
--------------[ Backup Statistics ]--------------
StartTime 1607801828.96 (Sat Dec 12 20:37:08 2020)
EndTime 1607801828.96 (Sat Dec 12 20:37:08 2020)
ElapsedTime 0.00 (0.00 seconds)
SourceFiles 2
SourceFileSize 100004096 (95.4 MB)
NewFiles 0
NewFileSize 0 (0 bytes)
DeletedFiles 0
ChangedFiles 0
ChangedFileSize 0 (0 bytes)
ChangedDeltaSize 0 (0 bytes)
DeltaEntries 0
RawDeltaSize 0 (0 bytes)
TotalDestinationSizeChange 20 (20 bytes)
Errors 0
-------------------------------------------------
And we will get files for incremental backup in the directory along with the old ones.
-rw------- 1 w w 170 gru 9 duplicity-full.20201212T193529Z.manifest
-rw------- 1 w w 96M gru 9 duplicity-full.20201212T193529Z.vol1.difftar.gz
-rw------- 1 w w 573K gru 9 duplicity-full-signatures.20201212T193529Z.sigtar.gz
-rw------- 1 w w 149 gru 12 duplicity-inc.20201212T193529Z.to.20201212T193708Z.manifest
-rw------- 1 w w 20 gru 12 duplicity-inc.20201212T193529Z.to.20201212T193708Z.vol1.difftar.gz
-rw------- 1 w w 45 gru 12 duplicity-new-signatures.20201212T193529Z.to.20201212T193708Z.sigtar.gz
As we want to send our data to a public cloud we need to make sure everyghing is encrypted so that nobody can look into our data and digitally signed to prevent any tampering. To achive this goal duplicity uses GPG. You have two options to chose - symmetric and asymmetric encryption. Symmetric one will use algotithm like AES and you will be able to encrypt and decrypt the data by providing the same password. This option does not let you to sign the archives, so to make sure nobody changed your backup you would need to keep the manifest files elswhere as they contain a hash (SHA1 hash that’s rather a poor option) that is verified. If you go the asymmetric route you will need to generate a pair of a public and a private keys. This will give you more options likes automatically signing of the archives or not storing decryption info on the machine doing backups (it will not be able to do a restore) the drawback is that you need to keep a pair of keys that cannot be lost and it’s not the best idea to keep them next to backups.
AWS S3 is a cloud based storage (one of many) that lets you upload and download files from CLI (Command Line Interface) tool which is what we need to make this fully automatic. S3 pricing can be found here. There are different classes of storage provided by S3. We will focus on three: S3 Standard - IA (Infrequent Access), S3 Glacier and S3 Glacier Deep Archive and we will refer to the first one as a hot storage and the rest as a cold one. Here’s a short summary:
| Storage class | Price per TB per month | Availability | Retrieval time | Retrieval cost per TB | Minimum storage duration charge |
|---|---|---|---|---|---|
| S3 Standard-IA | $12.5 | 99% | milliseconds | $10 | 30 days |
| S3 Glacier | $4 | 99.9% | minutes (more expensive) or hours | $2.5/$10/$30 | 90 day |
| S3 Glacier Deep Archive | $0.99 | 99.9% | 12 hours | $3/$20 | 180 days |
One more thing worth mentioning is that all data transfers to AWS are free of charge but they charge a whopping $90 for 1 TB out. HPE CEO Meg Whitman called this pricing model a Hotel California. You check in and you do not check out, otherwise it gets immendely expensive. Having HDD in the price range of $30 / 1TB it makes perfect sense to do a backup to a local HDD and AWS simultaneously and to serve virtually all your restores locally leaving AWS backup only for total disaster. This use case will set you back only around $1 per TB of storage and no other fees.
In this article to keep things simple we will make only a single copy right to AWS. This can be done in only a couple of lines:
1 duplicity -v info \
2 full \
3 --file-prefix-manifest=d_man \
4 --file-prefix-archive=d_arch \
5 --file-prefix-signature=d_sig \
6 --asynchronous-upload \
7 --tempdir=/dev/shm \
8 --volsize=650 \
9 --include=/mnt/disk1 \
10 --include=/mnt/disk2 \
11 ${SRC} ${DST} 2>&1 >> ${LOGFILE}
In line 1 we specify a log level info (quite verbose). Line 2 forces a full backup, lines 3 to 5 specify file names generated by duplicity. We will need specific file names later. Line 6 turns on asynchronous upload, this will let you to create new volume while still sending the previous one. This requires you to have 2 x volsize free disk space, but makes optimal use of resources (cpu and network bandwidth) which speeds the thigs up. Line 7 selects a place for our volumes before they are sent to AWS. As I was running this on a Raspberry Pi I wanted neither to wear the SD card nor to write it back to the original HDD as they are terrible at serving two locations simultaneously. /dev/shm seems to be a perfect place for short living data as it is kept in RAM, you only need to make sure the volsize remains small especially for memory-constrained devices. Line 8 specifies volumes’ size im megabytes. To restore a file you need to download a full volume regardless of the file’s size. So keeping huge volumes makes your restore slower and possibly pricier. On the other hand you possible don’t want 10000 volumes for your backup. I’m about to change to 4GB (fits on a FAT32 FS and a DVD/Mdisk) but you may find different size working for you better. Line 9 and 10 are the locations that we keep our precious data. For more complex patterns we may need also –exclude and/or use a pattern. SRC is the prefix path, in this case ‘/’ and DST is a destination like another directory or a cloud.
A working AWS version will look like this:
1 export PASSPHRASE="password_for_data_encryption"
2 export AWS_ACCESS_KEY_ID="will_get_one_later"
3 export AWS_SECRET_ACCESS_KEY="will_get_one_later"
4
5 DST="s3+http://my-own-s3-bucket/"
6
7 duplicity -v info \
8 full \
9 --file-prefix-manifest=d_man \
10 --file-prefix-archive=d_arch \
11 --file-prefix-signature=d_sig \
12 --asynchronous-upload \
13 --tempdir=/dev/shm \
14 --volsize=650 \
15 --include=/mnt/disk1 \
16 --include=/mnt/disk2 \
17 / ${DST} 2>&1 >> logfile.log
We just made our first backup to could. A very expensive backup. The reason is that we are using S3 Standard at $23/TB. To change this we have to log in to the AWS Console and do some tricks. We will configure AWS to move our backup from expensive to cheap storage automatically a so-calles lifecycle rule. First open S3 console and select your bucket. Go to management -> create lifecycle rule and you will see this form:
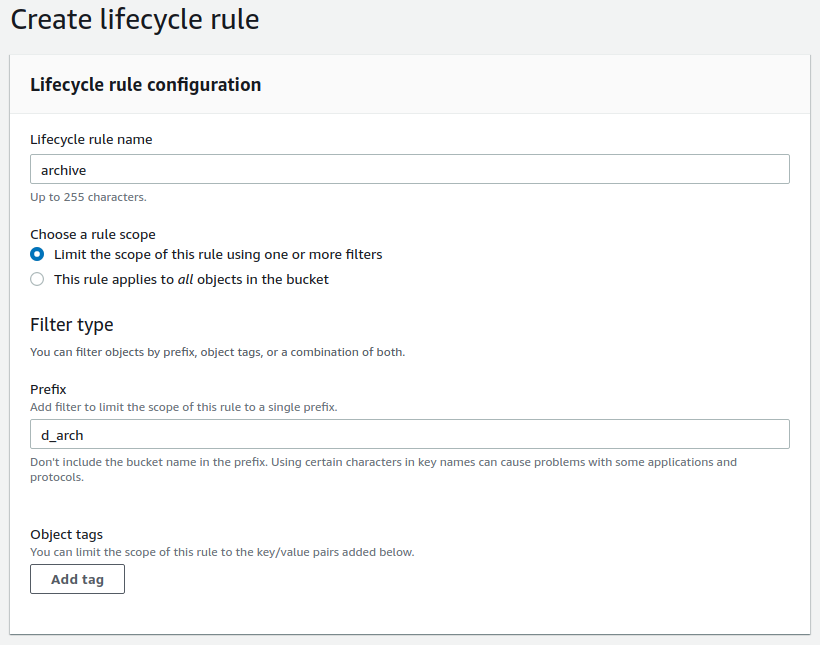
Give your rule a name, here “backup”, select file names the rule applies to, here “d_arch”. These are the only chunky files we have. It makes little sense to move other files as they are smaller and possibly needed to create new backups and we do not want to read from the glacier classes unless absolutely required.
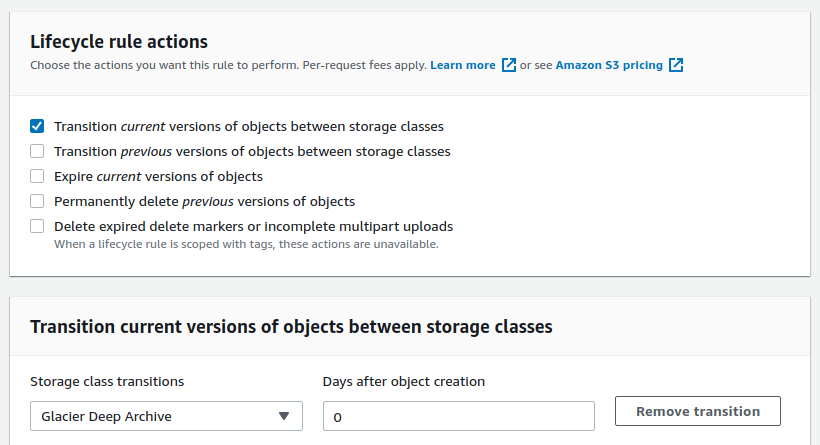
Set transition time to 0 days this will make your files to migrate soon after being added reducing the use time of high cost storage. CLick “create rule at the very bottom and now you are done. You may consider adding automated removal of old backups from glacier by adding expiration rules, or you can manually remove them after half a year or more (you alway pay for half a year upfront in glacier deep arhive).